Scientific American I think it was did a study in the early 70’s on the efficiency of locomotion. What they did was for all different species of things on the planet – birds and cats dogs and fish and man and goats and stuff – they measured how much energy does it take for a goat to get from here to there… and they ranked them and published the list, and the condor won, it took the least amount of energy to get from here to there, and man didn’t do so well, came out with a rather unimpressive showing about a third of the way down the list.
But fortunately, someone at Scientific American was insightful enough to test man with a bicycle, and man with a bicycle won—twice as good as the condor, all the way off the list. And what it showed was that man is a toolmaker, has the ability to make a tool to amplify the amount of inherent ability that he has.
And that’s exactly what we’re doing here. We’re not making bicycles to be ridden between Palo Alto and San Francisco… but in general we’re making tools that amplify the human ability.
Rumor has it that there’s an extant Stata bundle for TextMate. The original package link is a dead, but Gabriel Rossman was kind enough to send me a copy of his installed bundle.
With thanks to the author, Timothy Beatty, here’s the original bundle:
For those wanting a little extra functionality, George MacKerron described a method to add tab-completion for Stata variables. I’ve added his code to this version of the Stata bundle. (N.B. If your Stata application is not named “Stata”, you’ll need to make one small change. Open TextMate’s Bundle Editor; then, in the Stata bundle’s Complete Variable command, change the “appname” variable in line 6 to reflect your app’s true name, e.g. “StataMP”.)
Update: I’ve learned that two forward slashes can also be used in Stata for comments, including inline comments. To properly highlight this in Textmate, open the Bundle Editor > Stata > Stata. At the end of this file is the ‘comment.line.star.stata’. Change the match line to this:
match = '((^|\s)*|//).*$';
(N.B. As Sean points out below, make sure the single-quotes are straight, not curly, when you paste this line. Otherwise TextMate will throw an error.)
I am, of course, referring to Evernote, a tool that’s designed to remember everything you throw at it – then provide access to your information from virtually anywhere.
If you’re unfamiliar with the tool, this video will give you a quick picture of what it does:
Despite the obvious awesomeness of its sync/access capabilities, earlier iterations of Evernote failed my acquired-information management criteria on numerous counts:
It couldn’t accept basic documents like PDFs (flexibility fail)
It wasn’t scriptable (extensibility fail)
You couldn’t import/export data en mass (openness fail)
But the Evernote team have been hard at work, and with the recent addition of scriptability and an API, it’s worth a serious second look.
Accessibility: 9/10
Accessibility is undoubtedly where Evernote shines: you can access your data on the web client, your Mac or PC, or your iPhone or Windows Mobile device – and it all stays synchronized. Ergo, you still have your data when the network goes down. (The mobile Evernote clients act more as search/input portals into your Evernote data, though the latest iPhone version now stores your “favorites” locally so you can access critical notes offline. Also, if you prefer to keep some data private, you can selectively opt out of synchronization.)
Besides being Evernote’s killer feature, accessibility is also the cornerstone of the product’s business model: Evernote itself is free, but if you need more than 40MB/month you’ll need to upgrade to the premium version ($5/month or $45/year). The most exciting Evernote use cases will probably be mashups that use its API, which means increased bandwidth needs – and, therefore, subscriptions. (N.B.: Evernote’s API documentation describes the bandwidth elements as the “accounting structure”.)
Flexiblity: 4/10
Evernote accepts text/RTF files, images, web clippings, PDFs, and audio notes. To get files in, you can drag-and drop files onto the desktop client, email them to a special Evernote email address, or use the bookmarklet to clip content directly from any web browser. Handily, if you have part of a web page selected, the bookmarklet just saves the selection. Read: Evernote is most in its element when used for web clippings.
In addition, images can be snapped from your webcam or iPhone camera. More on this later.
Unfortunately, Evernote can’t handle many common document types, including Word documents (though RTF documents work passably). Most other filetypes (mind maps, outliner documents, etc) are out of the picture as well.
In the Mac client, the built-in content editor is little more than a glorified text editor. Text formatting is limited to font/size, bold/italic/underline, and alignment, though you can also attach images. (Not to mention the insulting font selection, which includes Arial but not Helvetica – shame!) The Windows client also provides some drawing tools (useful with a tablet PC), a broader font selection, and outlining functions. Update 11/10/08: Version 1.1.6 for Mac introduces orderd/unordered lists and tables.
Scalability: 6/10 (est.)
I haven’t thrown a tremendous amount of data at Evernote yet, so it’s unclear how performance is affected by a large data set. (I was hoping to put it to the test via the Delicious bookmark import, but Evernote just imported the bookmarks as links, rather than scraping the bookmarks’ targets.)
From a user interface perspective, scalability may be a problem. Items are accessed by browsing (by tags and metadata) as well as search. Aside from the ability to use multiple “notebooks”, there is no standard hierarchical organization. Users with a large number of tags or documents might become frustrated by this.
Searchability: 8/10
Basic search functions are solid, though generally unremarkable (no regular expressions, no advanced operators). You can combine search terms with tag filters.
In addition, Evernote has a couple search tricks up its sleeve:
Images pass through Evernote’s OCR engine when synchronized, turning image text into searchable data. This even works, to a large extent, on handwriting – slick!
Evernote metadata includes standard text tags as well as optional location data, so you should be able to search by location as well as content
Extensibility 7/10
The Mac client now includes a basic AppleScript dictionary, which allows for integration with other apps. No content-level scripting, but the most important feature – note creation – is available.
In addition, the Evernote API provides full access to Evernote data. I’m not aware of any Evernote-based applications yet, though Pelotonics is planning some level of integration. If useful integration emerges, this is will be a big win for users.
Openness 4/10
Disappointingly, despite claiming export options as a feature, Evernote maintains a tight grip on your data. Need to send a file to your colleague? Forget drag-and-drop: you’ll need to go through Evernote’s export or email functions.
On the Mac side, the only export option produces a proprietary Evernote-formatted XML file with document contents embedded. The Windows client can also export in HTML, web archive, and text formats.
When emailing files, Evernote wraps most notes in an ad-encrusted PDF document before sending. (Yes, it’s as bad as it sounds. Look for the “Plain text note” here. That PDF is what you get when you try to email a text file.) Mercifully, you can email PDFs in their original form – though whether this is by design or oversight is unclear. What is clear is that Evernote doesn’t make it easy for you to use your data as you wish.*
A third option is to share your documents in a public notebook (like this one). This of course not the same as export, but it does provide a refreshing level of social openness uncommon in tools of this nature.
Final thoughts
Evernote deftly handles web clippings and snapshots, and ubiquitous access makes it a viable tool for web research and data management.
Perhaps paradoxically, Evernote’s impressive accessibility also limits how I use it. Synchronizing data through Evernote’s server means I won’t use it for sensitive data. So although it’s hard to imagine a situation in which I won’t have access to my iPhone, Mac, or a web browser, it’s also hard to imagine a situation in which said access is truly critical. So I typically use Evernote for less important (but nonetheless useful) tasks:
Clipping captioned images and business cards for OCR
Jotting beer-tasting notes
Snapping photos of the same
Misc. data capture when I’m away from my computer
Bottom line: despite its limitations, Evernote is a great tool. At the free price point, you’re unlikely to find a more robust tool… so give the elephant a whirl.
*Comparisons could be drawn to DRM-laden music purchased from iTunes: it’s quite likely that you’ll never want to use it outside the iTunes/iPod ecosystem. But if (or when) that day comes, you won’t want to deal with their restrictions on your data. Same principle.
Update: 1Password bookmarklets are back, so please disregard this post.
The 1Password iPhone application is now available for download from iTunes (link here). The benefits of the iPhone app are clear: true data synchronization; intuitive interface with multiple levels of security; robust enough to handle thousands of passwords.
But there’s a catch: the updated 1Password desktop app will no longer export to the login bookmarklet. iPhone users: the 1Password app doesn’t integrate with Mobile Safari, so using the iPhone app will box you into its integrated browser. Firefox users: you’ll need to use the less convenient web page export.
Fortunately, Agile Web Solutions makes old versions available for download, so you can always revert to version 2.7.2, the latest version to support bookmarklets. At present, you can switch back and forth between versions (though I can’t say this won’t cause issues) to get the best of both worlds.
Success in the information age hinges on managing the explosion of available information in meaningful ways. To even approach this goal requires a successful information management strategy, which revolves around the questions
“How do I find relevant information?”
and its corollary:
“How do I manage the information I’ve found?”
On a personal note, these are two of the questions that drive my own technological explorations. Brainstorming and note-taking methods and tools provide another side to the issue. This post is intended to provide some background and framework for said exploration.
How do I find relevant information?
Online information is typically located through complementary methods of search and discovery.
Traditionalsearchtechnologies will long remain the first resort for information-seekers. Desktop search clients are also available for advanced data mining and research. Yet the rising semantic web is the true future of the Internet, and will enable users to interact with information in more meaningful and relevant ways.
Relationship-based information discovery is rapidly adding an important layer over traditional search tools. Social microsharing platforms (e.g., Twitter) and more robust social platforms (e.g., Twine, in private beta) allow individuals to build a liminal space of like-minded individuals with similar interests.
Two points are worth iterating here:
Social networks are becoming a search sphere in their own right. For me, the Twitter ecosystem has become my trusted first source of user opinions; for many types of information, I search on Twitter before going to Google or DEVONagent.
More and more information is shared and recommended through these relationship-based services. In other words, social networking platforms allow information to be discovered rather than explicitly sought.
Search once, not twice
The key to a useful information management strategy is this: You should only have to find a piece of information once.
Search tools should not be relied upon to find specific pieces of previously located information. If it takes more than fifteen seconds to locate online, it should be in your personal information system, not left to The Google.
If you spend a lot of time looking for information you’ve already encountered, your system is broken and you’re wasting your time. Or your employer’s time. Either way, that time should be spent turning information into knowledge, or putting it to use.
So: what to do with all this acquired information?
Accessible — it’s available when and where you need it (for both archive and retrieval)
Flexible — able to accept input from any variety of sources
Scalable — can accept many thousands of documents without becoming unwieldy
Searchable — the system is worthless if you can’t find what you’re looking for
Extensible — it can be extended through scripting or other means
Open — It doesn’t hold your information hostage when you need to change systems
The most rudimentary means of storing information – file systems – fail where it matters most. Because file systems are not designed for this type of data management, they are not truly accessible (saving an excerpt from a website, for instance, is a many-step operation), or quickly searchable (your data are hidden amongst tens of thousands of irrelevant system and program files). In addition, file systems don’t provide end-to-end data functions, so viewing the contents of most file types requires launching another application. Add-on tools like Google Desktop mitigate some of these issues, but they’re no match for a real EDM system.
True EDMs are specifically designed for the task archiving and retrieving information. They can store images, text clippings, and documents of all types; add content indexing to the mix (allowing users to search by any word contained in their files); and are streamlined to allow quick archiving of information. EDMs can be implemented as software-based solutions (see Yojimbo, EagleFiler, and the like), as well as online (see Google Notebook, for instance).
Second-generation information managers like DEVONthink and Twine take content management a step further, adding semantic intelligence and useful content analysis to the user’s database. DEVONthink, a tool that I’ve used for years, analyzes the contents of its articles to identify non-obvious semantic relationships and assist with automatic filing. Twine performs similar functionality in the context of a social network, in theory promising to integrate the most relevant search, discovery, and EDM tools.
Live in the cloud…
As computer usage becomes increasingly network-centric and social, individuals are becoming more and more willing to trade privacy for the convenience and utility of web-based services.
Put another way, we are becoming more willing to keep our information in “the cloud”. (I like the cloud metaphor because, for me, it conjures images of Benjamin Franklin flying his kite in the electric storm. There is energy and power and excitement in the cloud. There’s also risk.)
This trend will spell dramatic shifts in EDM solutions to come. Soon all our data will be accessible from any web-enabled smartphone or computer, anywhere in the world. (And with customs agents able to search the contents of any electronic device with impunity, business travelers may soon be required to keep sensitive data online, not on their machines.)
But online services are not a silver bullet—yet. As a general rule, the current generation of Web 2.0 apps:
Make it difficult to work offline (technologies like Google Gears may soon obviate this concern)
Don’t take full advantage of OS-level services, keyboard shortcuts, etc
Are not easily automated or scriptable
Make it difficult to back up files (FUSE applications may change this in the near future)
Put users at the mercy of others for data integrity (Granted, it’s vastly more likely that you’ll lose data from your own hard drive crashing – rather than Google’s servers going kaputt – but either scenario is a possibility. Pick your poison)
…with your feet on the ground
Until these concerns can be fully mitigated, the most promising path forward lies in hybrid desktop/web platforms that allow users to maintain local and online control of information.
These may be end-to-end solutions (for example, the NewsGator family of products includes web- and software-based newsreaders that are fully synchronized) or more specific sync services (Plaxo, for instance, synchronizes desktop calendar and address book clients with online equivalents). When implemented correctly, these tools can be phenomenally useful.
I’ve been waiting for this same innovation to make its way to the world of EDM apps, and there are some promising options emerging. A limited example is DEVONthink Pro Office, which has a built-in web server that provides remote access to your database. (First impression: it’s slick, but you’re out of luck if you’re stuck behind a firewall or the database isn’t running.) Evernote is a new EDM tool with full desktop-to-web synchronization tools, as well as limited online editing.
The beginning
Ultimately, any EDM solution is only a tool — but it may be the most important tool in the arsenal of knowledge workers. It is therefore of critical importance that we take our EDM strategies seriously.
You may not yet have an EDM strategy. But creating one may be the most important step you can take in your development as a knowledge worker.
Take a moment to think about how you manage what you know. Start exploring technologies, asking how they can improve your knowledge set.
It may take months to work out a reasonable system of your own… but it’s a beginning, and one well worth making.
OmniFocus rocks. I can’t really imagine managing myself personally or professionally without this tool. Nevertheless, despite thousands of hours of development and beta testing, it has its share of quirks. Notably, in my work I have a few daily-type tasks I set to repeat every day. Unfortunately, there’s no “workday” option in the repeat choices, so every weekend I end up with a Saturday and Sunday repetition. I could either:
Mark them complete (ignoring the fact that I’ve just claimed to have done nonexistent work);
Mark them complete and delete the “done” items before they disappear (solving the first issue)
Change the start/due dates in the Inspector (cumbersome)
AppleScript to the rescue.
My Defer script allows you to defer, or ‘snooze’, selected projects or tasks by a given number of days. (Disclaimer for GTD pedants: my use of the word “defer” here is sanctioned by the New Oxford American Dictionary, not David Allen.)
Usage:
Select the task(s) and/or project(s) you wish to defer. Invoke the script from the toolbar or script menu:
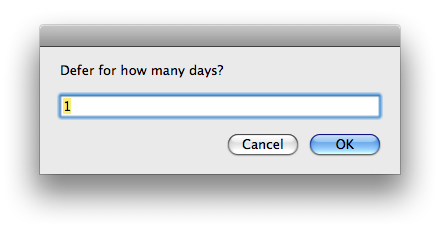
Enter the number of days to defer the items in the resulting dialog box and select “OK” (default is 1, so feel free to just hit Return to ‘snooze for a day’).
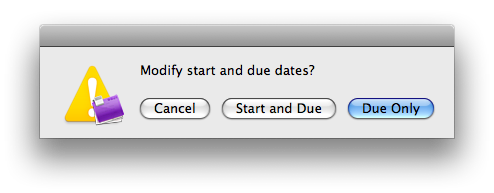
The script will then prompt you whether to defer both start and end dates of the items. “Due [date] only” is the default option, so again, feel free to hit return to snooze your due date only.
Finally: a Growl notification to signify your success. (If desired, you can use a standard OS alert dialog or no alert at all. See the script for details.)
XMind 2.2 was released last week. The upgrade introduces some improvements and bug fixes (list here), although printing remains buggy.
I’ve submitted formal feedback re: the printing issues; please do the same. Mango Software, the company behind XMind, have been very responsive to my emails in the past.
For what it’s worth, XMind is soliciting user feedback on the XMind user experience. I’ve already submitted comments regarding the quirks that bother me; please do the same!
XMind is a recently introduced mind mapping tool available for Mac OS X, Windows, and Linux. I purchased XMind several weeks ago and have found it to be a robust and rewarding tool, though it’s certainly not without its issues.
Basic features
Data entry – The ability to quickly add and edit information is the single most important feature of a mind mapping tool, and XMind makes input fast and painless. Return inserts a sibling topic, while Tab inserts a subtopic. (This is a faster interface than MindManager, for instance, which requires command-Return to insert a subtopic.) Return inserts a sibling topic. Command-Return inserts a parent topic, and Shift-Return creates a sibling topic before the selected topic.
Navigation – With a single-button mouse, click-and-hold on any free space in the map to drag the map around. Even easier, right-click drag for instant dragging.
Labeling (tagging) and Notes – Labels can be added to any map item and used to quickly filter large maps. One suggested use would be to attach names to action items. Rich-text notes can also be appended map items, and edited in the map or a sidebar.
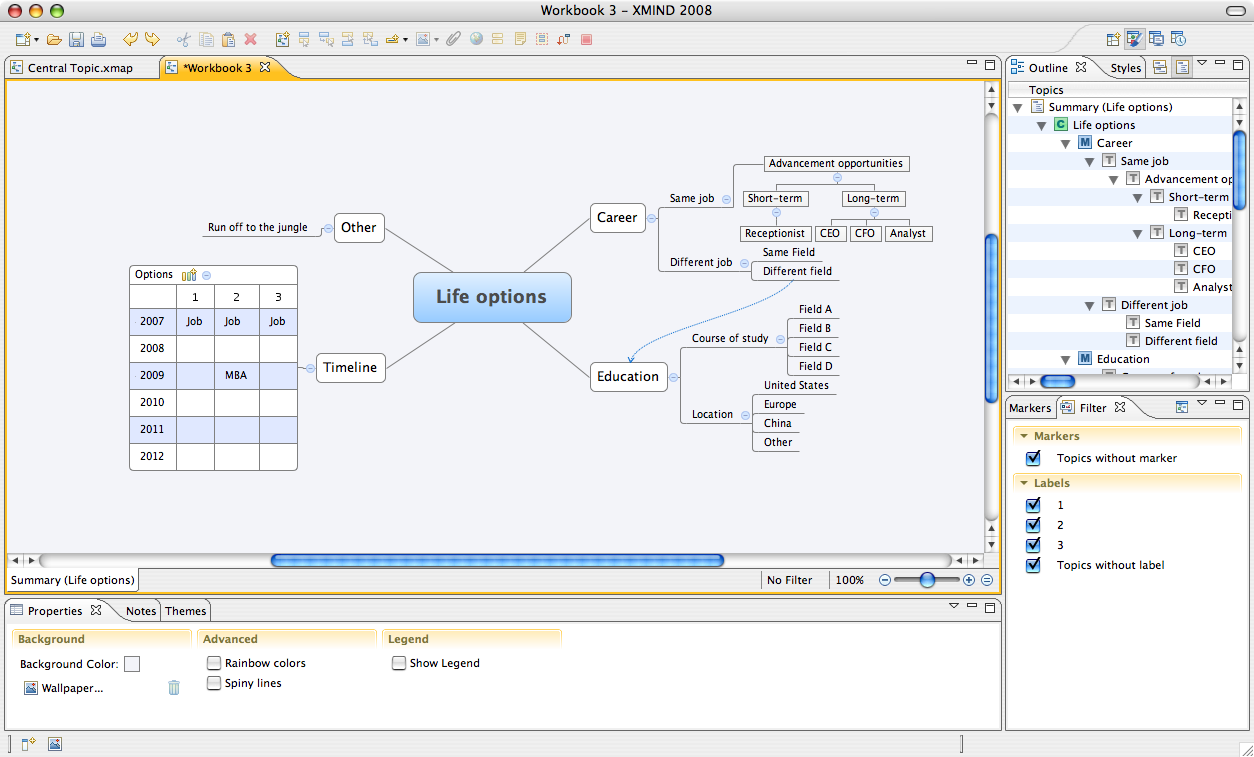
Visual editing – XMind includes a wide array of layout and editing options. Topics can be displayed with a variety of orders, from diamonds to callouts. Line options include simple curves, hard and soft elbows, straight lines and more. Spiny (thick) and rainbow lines are available as well.
Numbering options are basic but functional; for each level of the mindmap tree, you can select Roman numerals (I, II, III), Arabic numerals (1, 2, 3), and capital and lowercase letters (A, B, C or a, b, c). In addition, each sheet/tab can have a separate background color or image.
Visual Themes – Most usefully, XMind supports visual themes, which can expedite editing multiple documents. To create a theme, simply edit your document as desired, then select “Extract theme”. A new theme will be created to match your current document styles.
Audio notes can be added quickly to a topic. They’re saved in MP3 format, although currently there doesn’t seem to be a way to extract your audio notes.
Killer feature: embedded layout options
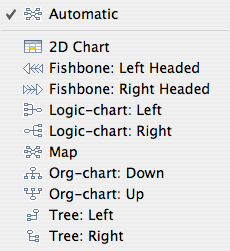
For me, the killer feature of XMind is the ability to utilize multiple layout structures within the same map. Options include traditional mindmapping structures (map, left tree, right tree, logic charts, org charts) as well as 2D chart (analogous to a spreadsheet clipping) and fishbone diagram options.
Although other mappers have this feature, its XMind offers more flexibility than its Mac OS-compatible counterparts.
(Click for full size)
Quirks
Editing
At present, there is no way to create a parent topic with multiple siblings selected; you must create the parent topic for one topic and drag other topics into it.
More frustrating, there is currently no keyboard-only option to edit a topic; typing overwrites the selected topic, so you need to use the mouse for this purpose. (XMind team: please fix this in an upcoming release!) [UPDATE: F2 now enters editing mode for the selected node.]
Format lock
While XMind readily imports from MindManager and FreeMind, it provides no way to save in other formats (MindManager, FreeMind, or even OPML). That said, if you desperately need to share your data, you can copy and paste into OmniOutliner. From there, export to OPML. Other programs can read this format quite easily. [UPDATE: XMind now exports to MindManager 7 format.]
That said, XMind documents have worked flawlessly between my Mac and PC.
Audio Notes
In the map area, you must double-click the Play button to play an audio note. Odd. [UPDATE: A single click now plays the note.]
Printing – caveat emptor!
[UPDATE: Printing has been improved significantly. Retaining this section for historical context, but note that many of these criticisms have been addressed.]
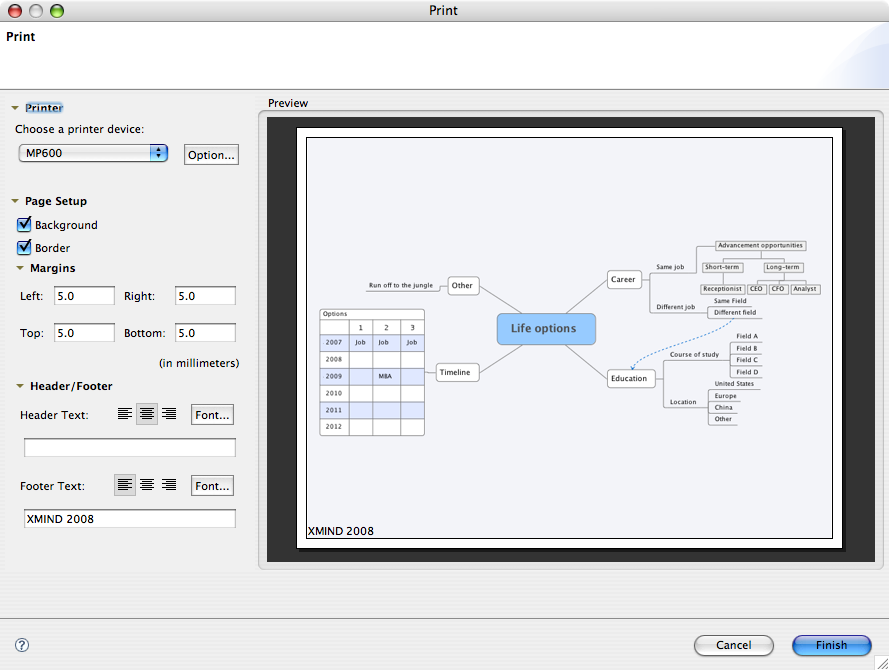
Printing in XMind is seriously flawed. To start, there is no Page Setup dialog box. Any page setup options are performed via a combination of the print dialog box and printer-specific settings. (To get a horizontal page layout, for instance, you have to go select the printer options setting, which brings you first to the OS X-standard Page Setup dialog box, then a Print window. Clicking “Print” from here does not print the document, as one might expect, but brings the user back to the Java print window.)
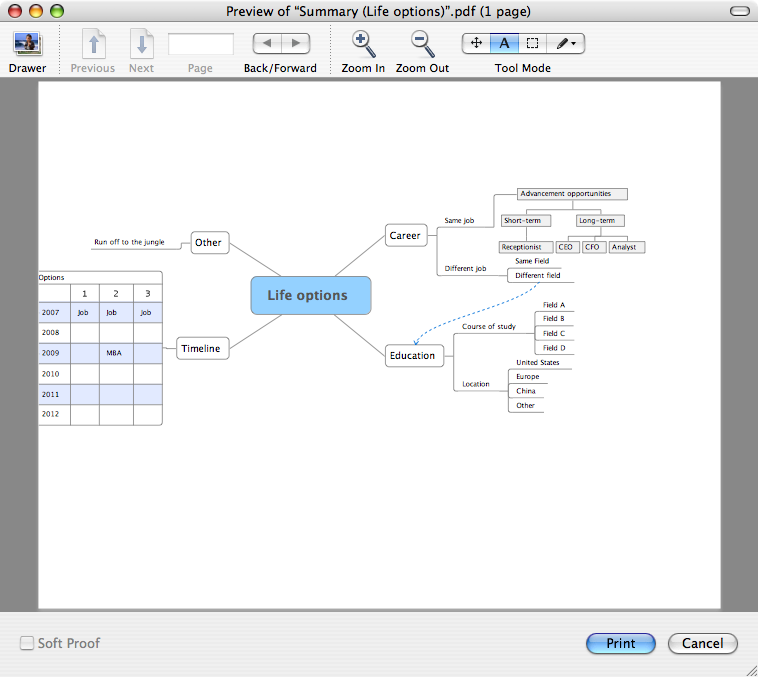
Worse, XMind has yet to learn the concept of a centered document. Printing with the default 5mm margins yielded a printout that was both off-center and clipped. I tinkered for a while and finally got a well-centered document with a 40mm left margin and 0mm right margin — though the built-in preview has no bearing on the final product. For example, this XMind preview:
…resulted in this print job:
To see what your document will actually look like without wasting paper, go through the printer options setting to the OS X dialog box. Instead of selecting Print, choose Print Preview. Although this will return you to the Java print box, when you finally choose Print you’ll get the Mac preview.
A note about Java
I expected Java to be a major issue for me. On the Mac, I want Mac-like apps with Services support, AppleScript options, etc. That said, XMind has done an amazing job harnessing elements of the Mac OS interface. Notably, it uses the native Mac open and save dialog boxes (failure to do so would have been a deal-breaker for me), and can summon Apple’s Color Picker utility instead of the standard Java fare.
Final thoughts
Although XMind feels like a late beta product, it’s a strong contender for the cross-platform mind mapping market. If on-screen editing (rather than printing) is your intended primary use, give it a whirl.
Also, to their credit, the XMind team have been very responsive — they have responded to several separate email requests and seem intent on improving the product.
Pros:
Extremely robust mapping options
Responsive customer support
Strikingly adept Java implementation on the Mac
Cons:
Printing is extremely frustrating
Java-based means no Mac OS Services; no AppleScript support
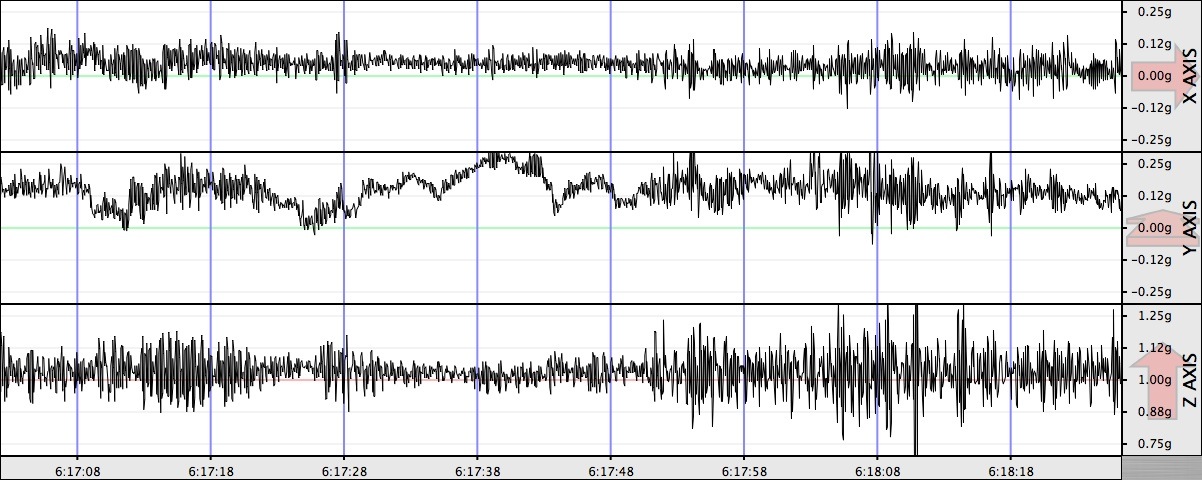
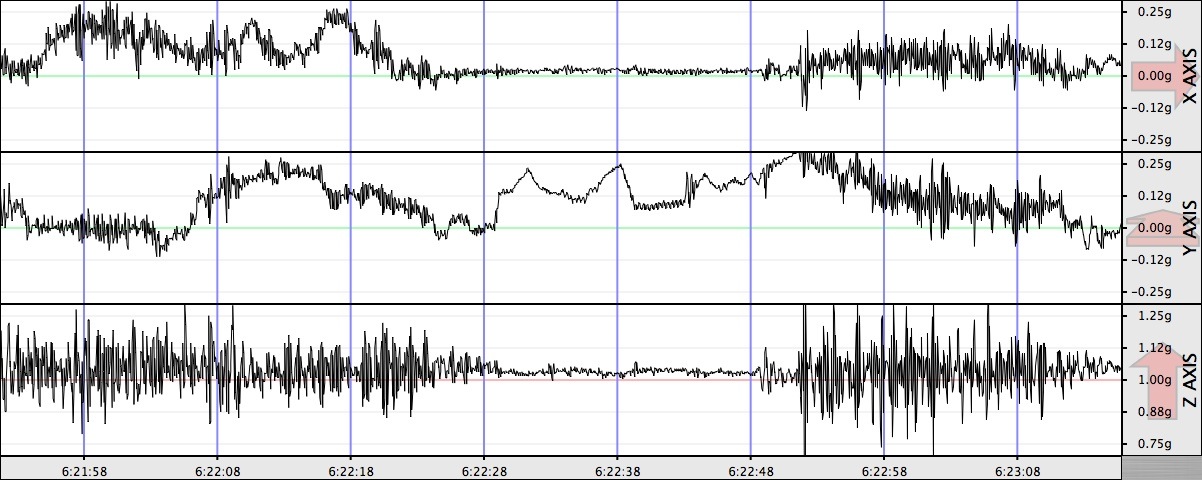
On a recent bus ride from work to the Vienna Metro station, I noticed the ride was rather rough and decided to take a closer look. Using SeisMac, a tool that uses my MacBook’s sudden motion sensor to take motion measurements, I recorded some key parts of the ride.
Because the computer was on my lap, the Y axis served as a crude accelerometer; when the bus accelerated, the front of the bus was raised a little (and I was therefore pitched back a little, causing the Y-axis reading to increase), and when the bus slowed down I was pitched forward, causing the Y-axis reading to decrease.
Exhibit 1: I-66
Getting on I-66, we began accelerating significantly at about 6:17:25. We hit traffic pretty abruptly and slowed down at 6:17:45, and then hit some rough potholes around :53 (see the Z-axis)…
Exhibit 2: Vienna Metro
Exiting I-66 to pull into the Vienna Metro station:
At 6:22:29, the bus was in a 3-way-stop traffic pattern at the Metro station (note how I was so violently pitched forward and backward). About 6:22:42, the bus made its final acceleration before letting the speed bleed off, coasting into its spot at the station.